
One of the largest benefits of having a YouTube channel is that people occasionally reach out to me to work on really great projects. Perhaps the coolest opportunity to come along was when a researcher named Chris Poulin contacted me to help him with an implementation of Deep Mind’s Agent57. For those that don’t know, Agent57 is a reinforcement learning agent that achieves superhuman performance on most of the games in the Atari benchmark, as well as achieving high scores in really hard environments like Montezuma’s Revenge. Needless to say, I was excited the prospect.
Agent57 builds on the work of a previous algorithm, called Never Give Up, or NGU for short. NGU is a boredom free curiosity based reinforcement learning method that, prior to Agent57, set the standard for performance in hard exploration environments. If calling it a boredom free curiosity based RL method is unclear, let’s indulge in a discussion how all this works before we get to the details on how the project went.
Curiosity Based Reinforcement Learning
One of the features of an environment that can make it especially difficult is the problem of sparse extrinsic rewards. In RL the agent uses the reward signal to develop strategies to navigate the environment, so the absence of these rewards poses a rather significant problem. One prominent example of such an environment is the Atari game Montezuma’s revenge. The agent has to navigate through several rooms to find a key, and then backtrack to use the key and receive a reward. It’s a non trivial sequence of steps that must be executed that are virtually impossible to find random actions.
The general solution to these types of problems is to leverage the agent’s curiosity. This is done using intrisic rewards that encourage the agent to explore as much of the environment as possible, to seek out those sparse extrinsic rewards. These rewards are often in proportion to the amount of “surprise” an agent experiences during some state transition. Here surprise can be measured in a clever way.
Surprise can be measured the agent’s inability to predict state transitions. We can compare predictions of state transitions to what actually happened to get a proxy for surprise, and give the agent a reward in proportion to its level of surprise. The greater the surprise, or inability to predict a transition, the greater the intrinsic reward. This has the benefit that it encourages the agent to seek out novel states, since it will eventually learn the environment dynamics for familiar states, thus reducing the intrinsic reward.
This is imperfect, however, as the agent eventually learns how to predict transitions with great accuracy. Intrinsic rewards thus approach zero over time, and if the agent hasn’t received sufficient extrinsic rewards, it may be unable to exploit a profitable policy for the environment. In colloquial terms, the agent gets bored with exploration and settles on a sub-optimal policy.
Another problem that can result is the issue of what I like to call navel gazing. If there is a source of random noise in the environment, the agent will be unable to predict the transitions, and will therefore receive a large reward for simply observing the noise. Needless to say, this is pathological behavior and discouraging navel gazing is a central problem in curiosity based reinforcement learning.
Both the issue of navel gazing and boredom were solved in a DeepMind paper from 2020, titled Never Give Up: Learning Directed Exploration Strategies. This built upon the prior work in the field of curiosity based reinforcement learning, and in true DeepMind fashion, blew the doors off the performance of previous algorithms.
Never Give Up
Overview
Never Give Up solves the issues of boredom implementing two different bolt on modules for an arbitrary reinforcement learning algorithm. In particular, the use of episodic and lifelong curiosity modules work to combat boredom.
The episodic memory generates intrinsic rewards for the agent, but combats boredom purging itself every episode. This means that every time the agent starts a new episode, what was old is new again and even transitions that have been encountered in 100 different episodes can still generate intrinsic rewards and keep encouraging exploration. Rewards are generated using a k-nearest neighbors algorithm where the reward is inversely proportional to the distance between neighboring points in our memory buffer. Distance is defined in terms of some abstract vector space, rather than pixel space itself, but more on that in a minute.
It stands to reason that eventually our agent will experience some extrinsic rewards, the maximization of which is the true goal of the reinforcement learning problem. We don’t want the agent to continue to solely pursue the intrinsic rewards, so we need some mechanism for allowing the agent to eventualy settle on a mostly exploitative policy that seeks out extrinsic rewards. This is the role of the lifelong curiosity module. Here we generate a multiplicative factor for the intrinsic rewards that amplifies their contribution to the learning signal at the beginning, and trends towards 1 over time. This gradually reduces the importance of the intrinsic rewards, without completely eliminating them.
Never Give Up Architecture
From the Never Give Up paper, we have the following diagram that encapsulates the above description of our architecture.
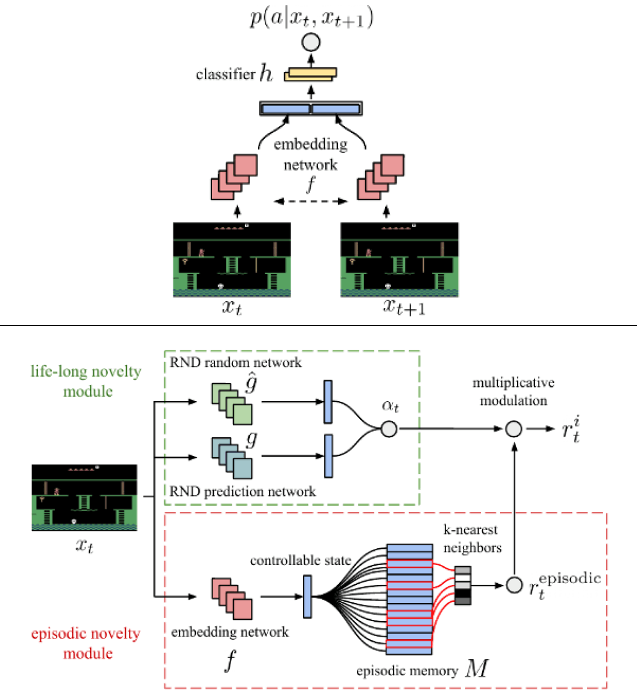
The solution to the problem of navel gazing is a little more subtle. In the above discussion we mostly talked about pixel observations. This was perhaps a bit misleading, but only for the sake of simplicity. In reality, the agent can’t really operate directly from the pixel space observations. They’re too computationally complex as well as being far too noisy.
From the diagram, we see that the pixel observations are passed into an embedding network. The embedding network transforms the pixel space observations into a single dimensional vector. It is the distance between observations in this vector space that form the basis for our K-nearest neighbors algorithm, and therefore the intrinsic rewards.
This emedding network acts as a sort of feature selector for our agent. We can train this network to hone in on the features of the pixel images that are meaningful (to the agent), and ignore everything else. By passing two successive screen images to our embedding network and asking the network what action was taken to cause that transition, and comparing that to the action the agent actually took, the agent learns the environment dynamics. In principle, there is no incentive for focusing on noisy aspects of the pixel images, and therefore the agent only learns what parts of the image change as a consequence of its actions. Thus, we can sidestep the issue of navel gazing entirely.
Now that we have some plausible mechanisms for how NGU solves the boredom and navel gazing problems, let’s see how all this works in a real agent.
The Never Give Up Agent
The lfelong and episodic curiosity modules are really just bolt-on components that we can add to any cutting edge deep reinforcement learning algorithm. One obvious candidate is Recurrent Distributed Deep Q Learning, or R2D2 for short. This is a modern algorithm, designed DeepMind, that was previously a benchmark for superhuman performance in the majority of titles in the Atari library. The TL;DR of this algorithm is that it is a dueling Q network architecture that incorporates recurrence (using an LSTM) and massive parallelization (64 actors and up).
Approximation of the action-value function Q is handled universal value function approximation (UVFA). Here the authors use a family of $Q(x, a, \beta)$ where the total reward the agent receives is given :
$$ r_{i}^{\beta} = r_{t}^{e} + \beta r_{t}^{i} $$
This $\beta$ belongs to a discrete set of values that serve as hyperparameters for our agent. It gives the absolute degree of weighting for the intrinsic rewards and allows us to interpolate between policies that are purely exploitative and strongly explorative.
Naturally, we still have our discount parameter $\gamma$, and in fact the combination of $\beta$ and $\gamma$ is an important knob in our agent’s performance. In the NGU paper, the DeepMind team use a sort of hard coded approach where they pick some set of values for the hyperparameters and conduct the entire training regime with those values. Then they can settle on a combination that produces great results across the Atari library, and call it good.
For details on the performance of NGU, I recommend checking out the associated video for this blog post. I go into detail on how this algorithm is tested, and how the solution to navel gazing and boredom is validated. For our purposes here, I want to move on to a discussion of Agent57 and how I came work on an open source implementation.
Beyond Never Give Up: Agent57
As powerful as NGU is, it is not without its flaws. Namely, our action value function utilizes the same network parameters for the intrinsic and extrinsic rewards, and we choose a static value of $\beta$ and $\gamma$ for the entirety of the training process.
Using a single network for the approximation of Q is problematic for a pretty simple reason. The intrinsic and extrinsic rewards tend to have vastly different scales. We’re not talking about a factor of two; there can be one or more orders of magnitude difference betwen them. This can result in training instability in Never Give Up.
Agent57 solves this breaking out the UVFA Q function into two components:
$$ Q(x, a, \beta, \theta) = Q(x, a, \theta^{e}) + \beta Q(x, a, \theta^{i}) $$
Where we have intrinsic and extrinsic $(\theta^{i}$ $\theta^{e})$ sets of parameters for our neural network. These are trained using the exact same memories from the buffer, but they are optimized with the intrinsic and extrinsic rewards respectively, and the same target greedy policy.
The issue with the choice of a single combination of $\beta$ and $\gamma$ is that this choice may not be ideal for the entire training cycle of our agent. In fact, it stands to reason that we would want to vary the weighting of our intrinsic rewards and discount factor over time, to enable more or less exploration at the appropriate time. In particular, higher $\beta$ and lower $\gamma$ (stronger intrinsic reward and more discounting of past rewards) would be better early in training, while lower $\beta$ and higher $\gamma$ would be better later on in training.
Agent57 deals with this implementing a meta controller that treats each combination as an arm of a multi-armed bandit, and selects an arm at runtime. Each episode can get its own combination of $\beta$ $\gamma$ and we can train this bandit using the total episodic return to maximize performance over time.
The end result of this is superhuman performance on all the games of the Atari library, including the really hard games such as Pitfall and Montezuma’s revenge.
How I Worked With a Ukranian Software Development Team to Implement an Open Source Agent57
With the technical details out of the way, let’s talk about how the project evolved over time.
When Chris came to me, he already had a number of positives going for the project. For one, he had a functional single threaded implementation of R2D2, based on DeepMind’s ACME framework. Another strong positive was that despite this being a project in the very early stages, he had made a connection with Adria (the lead author on both papers), which meant that if we could at least get close to the final goal, we could get some expert level hints to push us over the edge. So, when Chris proposed that I help him go from R2D2 to NGU, I was happy to begin on the project.
Frequent viewers of my work know that I tend towards a minimalist style in programming. This was no exception. How could I get a minimum viable implementation of Never Give Up going as quickly as possible? My vision of v0.1 was an implementation of the episodic memory module, with the parallelization and lifelong curiosity to follow in a v0.2. I set about this task using as much pre-built code as I could get my hands on.
This meant a heavy reliance on the ACME framework; the Tensorflow 2 implementation in particular. ACME is the very same framework that DeepMind uses to write their own agents, and I figured if it’s good enough for them, it’s certainly good enough for me. However, one of the downsides of choosing Tensorflow 2, as Academy subscribers know now, is that parallelization is all but ipmossible. None the less, I pressed forward.
Within a few weeks I was able to implement the core features required for my 0.1 vision. The episodic memory was functional, but testing quickly revealed a couple hard truths: namely that parallelization was going to be essential to the success of the agent, and that the lifelong curiosity module isn’t so optional after all.
Given the enormity of the project, we decided to bring on some additional help. At this point Chris contacted a development team known as SoftServe, based in Ukraine. This turned out to be great choice, as the team was highly skilled and experienced in implementing RL agents. Using my code as a template, they ripped out the Tensorflow 2 internals and moved to Jax, which is a much more multi-threading friendly framework.
The results were impressive. The team was able to implement all the core functionality of the NGU agent, as well as add in some quality-of-life improvements (such as improved checkpointing). Then they turned their attention to the split UVFA implementation and meta-controller, and voila, within a couple months we had a functional implementation of Agent57.
Obviously, there were hurdles along the way. Not the least of which is the (as of now) on-going Russian military operation within Ukraine. Thankfully, the entire team was able to stay safe and continue working on the project the entire time.
I’ll be preparing a YouTube video that goes over all this material, in a little more depth, as well as some results we obtained along the way. Please stay tuned to the channel for that.
If you’d like to check out the project, you can find our open source code here
And also, obligatory shameless self promotion. If you’d like to learn how to implement deep reinforcement learning papers, check out our Courses. There’s a discount for Udemy students, just shoot an email to sa***@*******et.ai