
Reinforcement learning algorithms tend to fall into two distinct categories: value based and policy based learning. Q Learning, and its deep neural network implementation, Deep Q Learning, are examples of the former. Policy gradient methods, as one might guess from the name, are examples of the latter.
While value based methods have shown performance that meets or exceeds human level play in a variety of environments, they suffer from some significant drawbacks that limit their viability across the broader array of possible environments. In particular, in Q learning, the agent is using the same network to both approximate the value of a given state action pair, as well as to choose actions. This can lead to chasing a moving target, as well as the presence of maximization bias, due to the argmax in the action selection process.
A further limitation of value based methods lies in the topology of the parameter space. The action value function can be quite complex, with many local minima that can trap the gradient descent algorithm and result in subpar play.
Policy based methods do not suffer from such drawbacks, as they are attempting to approximate the agent’s policy rather than the action value function. In many cases, this is a much simpler function to approximate and therefore the chances of getting trapped in local minima are reduced.
In traditional policy gradient methods, the agent samples rewards from the environment in a Monte Carlo fashion, and uses these to compute the discounted future rewards at the end of each episode. These rewards are used to weight the gradient descent such that the agent assigns a higher probability to the actions that lead to higher future returns, and less probability to those actions that lead to lower future returns. This can be clearly seen in the update rule:
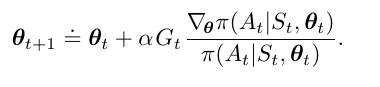
Note the presence of the gradient of pi divided pi. For those of you familiar with vector calculus, this is the unit vector in policy space.
Beyond the Monte Carlo implementation, there is a dizzying array of policy gradient algorithms. There are actor critic methods, that introduce an additional network to learn the action-value function, as well as algorithms for continuous action spaces. Of course, continuous action spaces are intractable with Q learning, and thus actor critic methods are uniquely suited for such environments.
Stay tuned for a future post detailing the implementation of actor critic methods for both discrete and continuous action spaces.
For a video overview of this material, check out the video below:
Thank you very much for the explanation!
I wanted to ask, could you provide some material about this or any proofs?
"Limitation of value based methods lies in the topology of the parameter space. The action value function can be quite complex, with many local minima that can trap the gradient descent algorithm and result in subpar play."
Btw it sounds good and I believe that it is as you said, but it seems like we have to be able to process every state to calculate the probability of the action, and doesn't it require solving almost the same parameter space complexity?