
Several years ago the Deep Mind team announced that they had designed a new reinforcement learning algorithm capable of beating human level play in multiple games from the Atari library. This new algorithm, deep Q learning, was the marriage of deep neural networks and traditional Q learning. Rather than being a trivial bolt on, deep Q learning is actually an ingenious solution to a difficult problem: how to handle the incredibly large state spaces of even primitive video games?
For those new to machine learning, neural networks are effectively function approximators. One can approximate nearly any function, provided it is continuous. This is particularly useful for modeling relationships between the large state spaces of environments and the value of an agent’s policy in reinforcement learning. In a nutshell, the policy tells us the present value of the expected future rewards the agent would receive, given it’s in some state and is following its policy. It’s a measure of how “good” a particular policy is, with respect to maximizing the agent’s future rewards.
But perhaps I’m getting ahead of myself.
Reinforcement learning is our best attempt at modeling a type of general intelligence in machines. It operates creating feedback between some intelligent agent and its environment. That feedback is mediated through the reward system, which tells the agent what is expected of it the environment. This is best summed up the ubiquitous diagram:
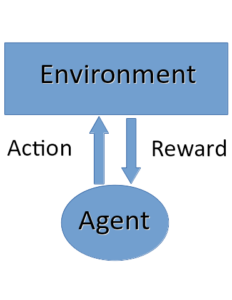
The algorithm governing how the agent responds to the inputs from the environment is called its policy. At a fundamental level, it’s a mapping between the state space and the agent’s actions. Policies come in a variety of forms. They can be completely stochastic, they can be completely greedy, but generally they are something in between.
Yet, there is a fundamental problem. The agent can never be quite sure it has found the optimal policy, meaning that policy that maximizes its potential future rewards. To what extent should the agent take actions that aren’t dictated its policy in an effort to realize the potential for even greater future rewards? This is known as the explore-exploit dilemma, and it comes with many creative solutions.
One such solution is to simply select random actions some fraction of the time, and the remainder of the time choose greedy actions. This enables the agent to explore parameter space over a large number of actions, while mostly maximizing its short term rewards. In Q learning, epsilon-greedy is used in tandem with what is known as off-policy learning. In that case, the agent maintains two policies. The exploratory behavior policy, epsilon-greedy in this case, is used to update the value function (well, technically action-value function) for the purely greedy target policy. To put it another way, the agent is using samples generated some off-policy strategy to update the value function for its true policy.
So that brings us around to the “deep” portion of deep Q learning. As I said above, neural networks are function approximators. In this case, we want to approximate the value of the agent’s policy. This approximation is required, as we often don’t have a complete model of the environment. In the case of even simple Atari games, the state space is astronomically large, and so we have no way of sampling enough of it to get the exact value function. The agent has to get with sampled state transitions, and an approximation of the value function generated a deep neural network.
We will explore the details of the deep Q network in a future blog post and associated YouTube video, but for now suffice it to say that the agent leverages a convolutional neural network to parse the input images from the environment, i.e. to reduce the dimensionality of the state space, and a dense fully connected network to approximate the value of each action for that state.
For a more detailed breakdown of the Q learning algorithm, please check out this article’s associated video:
Can you explain how did you use the batch inside your code in the learn function of the DQNModel() class?
I am struggling to understand how you are using these state_batch, action_batch etc and what do they exactly contain and how do we use it to train samples?
It will me much more clear if you can give an example for the same.
Thank you very much.
Hey Azlaan, the state batches contain the observations from the environment. So it’s a matrix of shape [batch_size x observation.shape]
Similar for the action batches, except the size corresponds to the action space.
We use the batch training to break the correlations between steps within an episode. If we just sample the states, actions, rewards, and new states from the episode we just played, then these are all highly correlated. The training of neural networks generally assumes all the samples are independent (that’s why we shuffle data sets when doing supervised learning).
By randomly sampling the replay memory we are effectively shuffling our data set, and allowing our neural network to learn more robustly.